Project 1 - RAG Search Assistant
Synopsis
RAG Search Assistant is a secure internal AI tool built for Aurenis, enabling staff to instantly query organisational knowledge using natural language. Designed and deployed end-to-end, leveraging Claude (Anthropic), Bedrock, Pinecone, Amazon Titan Embeddings and fully serverless AWS infrastructure.
Executive Summary
Aurenis, an under-performing Healthcare company, has faced 3 consecutive quarters of stagnation. Their recent lackluster performance is due in large part to the emergence of fierce new rivals who have made market conditions significantly more competitive. This has been borne out by the sudden loss of two of the business’s largest customers in quick succession. While both factors have had a devastating impact on Aurenis’ once-dominant market position, this alone does not represent the complete picture. For quite some time, Aurenis’s staff on the ground have been battling against a variety of operational challenges that have made it increasingly difficult for them to maintain the level of quality and output that had been a hallmark of the business to date.
Despite being notoriously risk-averse when it comes to embracing new technologies, the business imperative coupled with the arrival of an ambitious new CTO has compelled the firm to take immediate action. The company has decided to break with tradition and implement the latest AI enterprise software across their customer-facing teams. A new RAG Search Assistant tool will be aggressively rolled out among the Sales, Support and Operations Teams with the stated aim of shortening the time it takes to close new business, onboard customers and resolve customer issues, which in turn is expected to lead to vastly superior CSAT scores. It is hoped that the initiative will not only drive growth but propel Aurenis back toward the market-leading position it once held for many years.
Context
Aurenis, a medium-sized Healthcare company with a presence in 4 markets is facing a major inflection point. The business has consistently failed to meet the ambitious targets set by the Leadership team and investor confidence is at an all-time low, with the company share price veering towards terminal decline. If the business climate was unfavourable on a macro level, the sentiment among staff operating at the grassroots was decidedly worse.
A key bone of contention among workers in customer-facing roles has been the company’s over-reliance on outdated processes and systems leading them to experience constant burnout and the feeling of having to run on a perpetual treadmill merely to stand still. Customer service excellence is the company’s core value. It remains a deeply rooted part of its culture. Employees derive much of their self-worth from their ability to consistently over-deliver at speed, and so they feel deeply frustrated about having to spend a significant proportion of their time continuously trawling through Slack threads, Jira tickets and internal Confluence pages just to be able to locate the information they need to support customers. In fact, a recent audit revealed that over 200 hours a week are dedicated to this very task alone.
With key customers defecting to competitors due to the perception that they can be better served elsewhere, Aurenis’ newly-appointed CTO has identified this as a key area to address in order to reverse the company’s fortunes, and on a more personal level, make a major impact early on in his tenure.
Problem Statement
Fundamentally this project seeks to explore the extent to which the firm can reduce wasted time spent locating knowledge across tools, while improving employee morale and customer satisfaction.
In addition, the project aims to investigate the following key questions:
- Can access to business knowledge be centralised via natural language?
- Can AI tools be trusted to deliver accurate information free of hallucinations and other errors?
- Is such a tool intuitive to use and accessible to a wide pool of non-technical users?
- Does the tool’s presence directly correlate with increased customer satisfaction and employee morale?
- Can the tool easily be incorporated into Support teams’ day-to-day workflows without the need for extensive training?
- Does the tool require a substantial amount of maintenance and upkeep?
Together, these questions define the scope and criteria by which the success of the RAG Search Assistant will be evaluated.
Success Criteria
The success of this project will be determined by the following criteria:
- A fully secure system only accessible to authorised users.
- A user-friendly interface with low latency which encourages fast adoption.
- A stable and dependable resource that staff can consistently rely on.
- High levels of factual accuracy and contextual awareness in responses.
- The ability to tailor answers precisely to the user’s question and intent.
These criteria will guide how the project’s impact is assessed following implementation.
Functional Requirements
- Core Functionality
- The application must allow users to query proprietary company knowledge via natural language.
- It must return answers grounded in internal data (RAG-based responses).
- Responses must be tailored based on the user’s question and intent.
- User Interaction
- The app must deliver a smooth user experience, with responses returned within 2–3 seconds.
- The tool must be intuitive and easy to use.
- The product must integrate cleanly into existing Support workflows with minimal training.
- Security
- The application must support robust user authentication.
- Role-based access controls are essential.
Non-Functional Requirements
- Security
- Rate-limiting and DDoS protection must be enforced.
- IAM must ensure only authorised users have the appropriate level of access.
- The solution must observe compliance requirements with full logging and monitoring.
- Encryption
- In Transit: Data must be encrypted with HTTPS.
- At Rest: All stored data must be encrypted.
- Key Management: Key rotation must be automated and centrally managed.
- Fault-Tolerance & Availability
- Occasional outages are acceptable for an internal application.
- The system must be restorable quickly if it goes down.
- Scalability
- The system must scale to support ~30–40 internal users.
- Traffic patterns will be predictable with light morning spikes.
- Geographic Distribution
- User base is UK-only; multi-region deployment is unnecessary.
- Storage
- A vector store is required to hold embeddings.
- Object storage is required to store model artefacts.
- Operational Overhead & Management
- The solution should require minimal manual intervention.
- The Aurenis team favour serverless due to auto-scaling benefits.
Feature-to-Requirement Mapping
| Requirement | Mapped Feature / Service | Category |
|---|---|---|
| User Authentication | Amazon Cognito Hosted UI (PKCE) | Security |
| Secure API Access | API Gateway JWT Authorizer | Security |
| Rate Limiting & DDoS Protection | CloudFront + AWS WAF | Security |
| Data Encryption (In Transit) | HTTPS via CloudFront + API Gateway | Security |
| Data Encryption (At Rest) | Pinecone Serverless + S3 Default Encryption | Security |
| Key Rotation | KMS-managed encryption | Security |
| NL Querying | Bedrock Embeddings + RAG Pipeline | Core Functionality |
| Grounded Answers | Pinecone Vector Database | Core Functionality |
| Low Latency | Lambda + Bedrock (Claude Sonnet) | Performance |
| Content Delivery | CloudFront CDN | Performance |
| Serverless Scaling | Lambda | Scalability |
| Internal Throughput | API Gateway HTTP API | Scalability |
| Minimal Management | Fully Serverless Architecture | Ops |
| Simplified Deployment | S3 Static Hosting + Lambda Packaging | Ops |
| Storage | Pinecone + S3 | Storage |
Solution Overview
This section outlines the system design and implementation strategy for the RAG Search Assistant, highlighting architectural decisions, functional workflows, and non-functional considerations.
Key Architectural Decisions
Data Source & Embeddings
- BMW worldwide sales dataset (2010–2024), sourced from Kaggle.
- Structured, narrow domain makes it ideal for accuracy testing.
- Amazon Titan Embeddings used for embedding generation.
Vector Store
- Pinecone as primary vector database.
- Fallbacks: OpenSearch, Kendra, Bedrock Knowledge Bases.
Model Strategy
- Model-agnostic design, allowing easy swapping.
- Considered: Claude 3 Sonnet, Titan Text, DeepSeek V2.
Deployment Strategy
- Local development → Serverless production (Lambda + API Gateway).
- Low-maintenance, high-performance architecture.
Functional Flow
Phase 1: Data Processing
The following diagram outlines the embedding + indexing workflow:
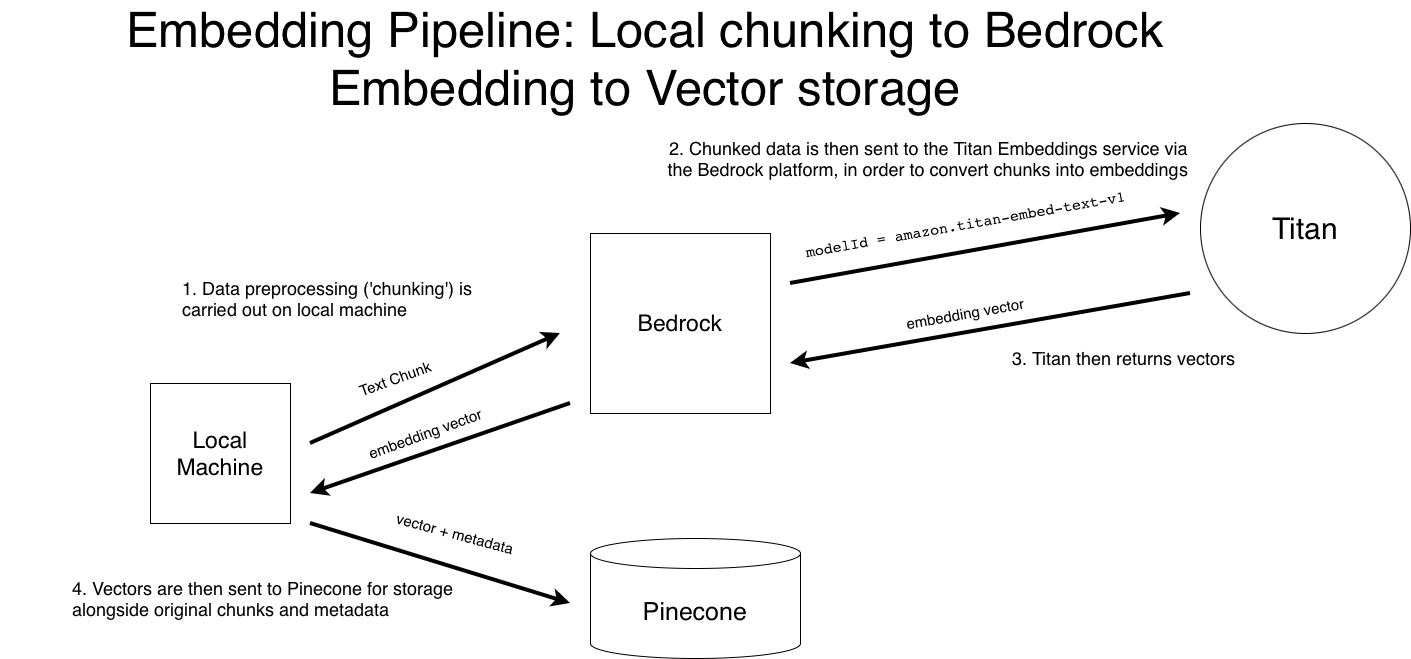
Workflow Summary
- Chunk raw CSV data.
- Embed using Titan Embeddings via Bedrock.
- Store vectors in Pinecone with metadata.
Phase 2: Retrieval and Generation
The diagram below visualises the runtime flow of query resolution:
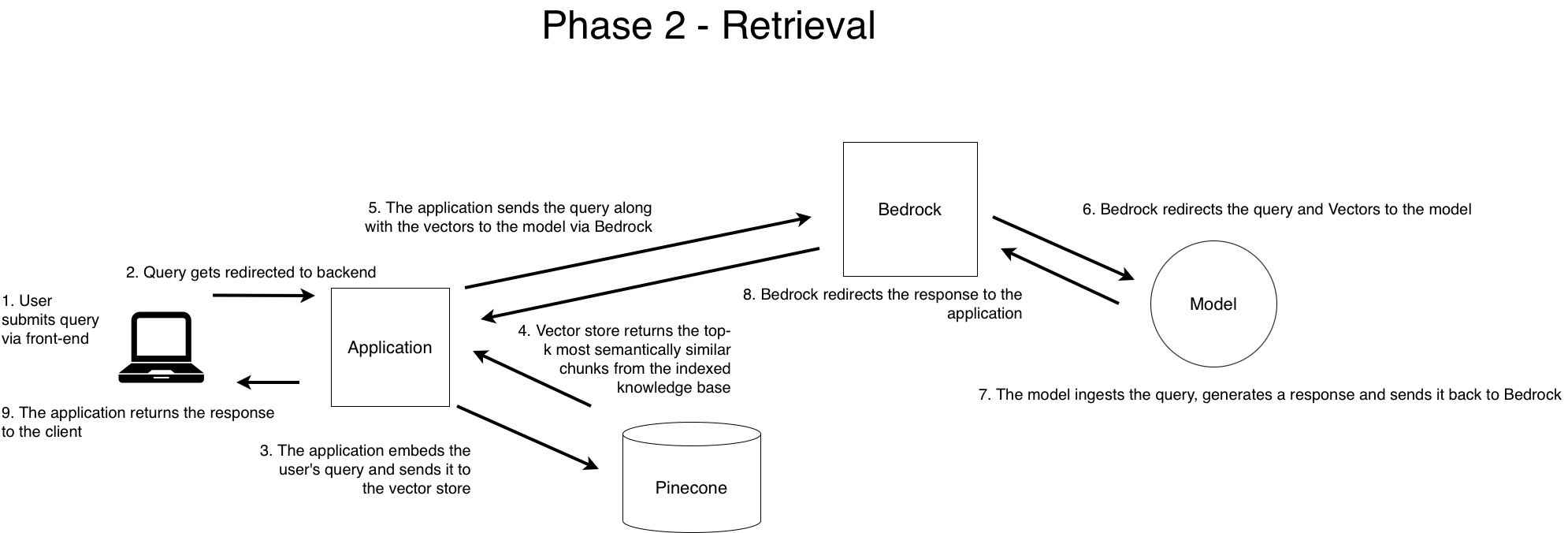
Workflow Summary
- User submits a query.
- App receives and processes query.
- Query is embedded → Pinecone top-k retrieval.
- Retrieved chunks + query → grounded prompt.
- Prompt sent to Bedrock.
- Model (e.g., Claude Sonnet) generates response.
- Response returned to app.
- App returns final answer.
Architectural Sequence & Runtime Architecture
The complete runtime architecture is illustrated below, showing how user identity, front-end routing, application logic, AI inference, and observability layers interact:
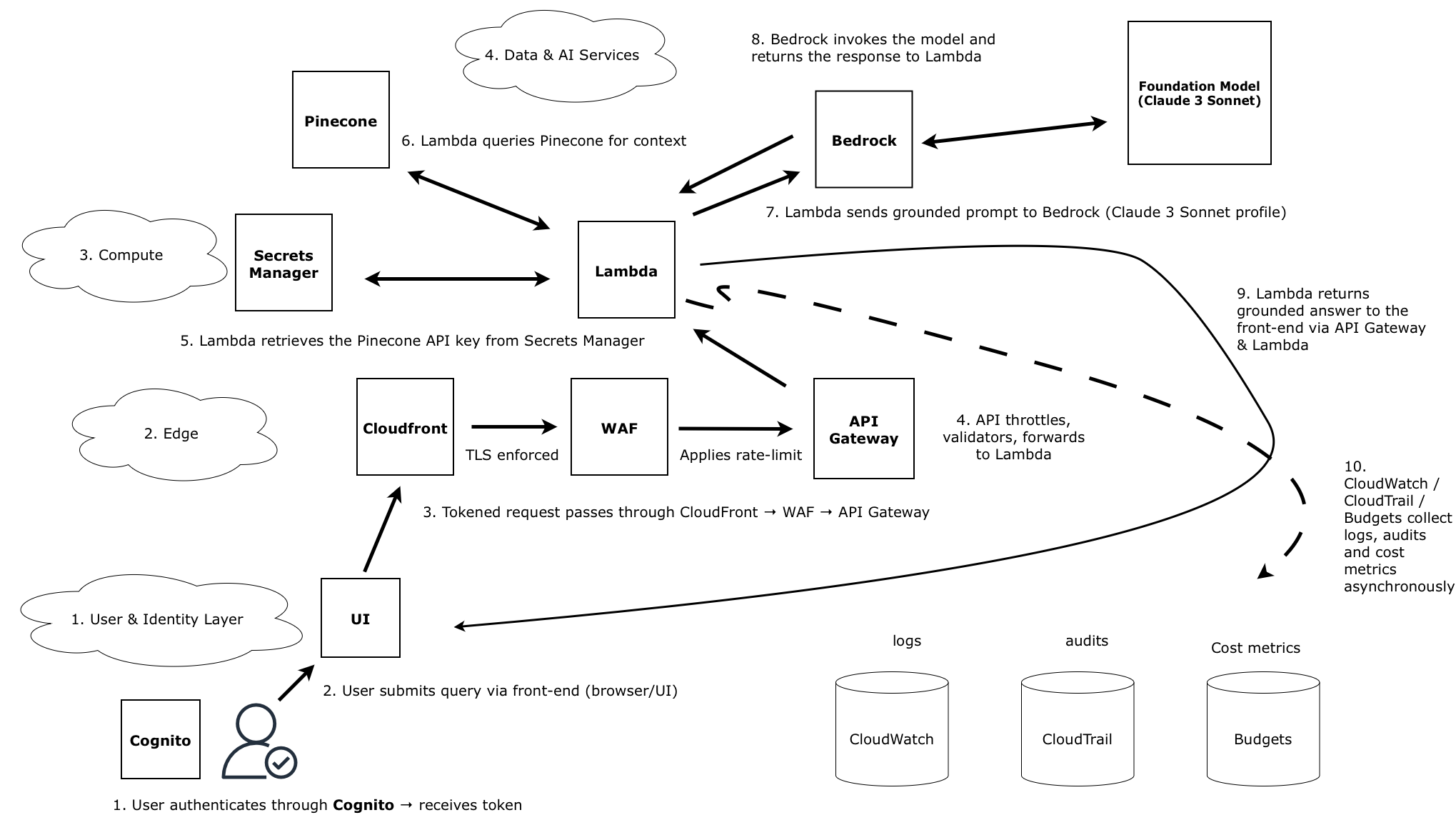
Identity
- Users authenticate via Cognito and receive an access token.
- The token is included with all requests to validate identity and authorisation.
Edge
- Requests pass through CloudFront, where TLS is enforced.
- AWS WAF applies rate-limiting and threat mitigation.
- Validated traffic is forwarded to API Gateway.
Application
- API Gateway routes valid requests to the Lambda function.
- Lambda retrieves API keys and secrets from Secrets Manager.
- Lambda queries Pinecone for top-k relevant context chunks.
- Lambda assembles a grounded prompt and forwards it to Bedrock.
Data & AI
- Bedrock forwards the prompt to the selected model (e.g., Claude 3 Sonnet).
- The model generates a grounded, context-aware response.
- Bedrock returns the output to Lambda, which forwards it to the front end.
Observability & Cost Control
- CloudWatch captures application logs and metrics.
- CloudTrail records all API activity for auditing.
- AWS Budgets monitors spend and triggers alerts.
Final Notes
This architecture reflects a scalable, low-maintenance deployment strategy that balances security, performance, and usability. All decisions were made with real-world adoption, developer efficiency, and measurable business impact in mind.
Implementation
Deployment Roadblock: Python Packaging on macOS for Lambda
Surprisingly, the most challenging part of implementation turned out to be deploying the application
to AWS Lambda. The process of uploading the application code from my local machine to Lambda took well
over an hour, before continually failing with an
Unable to import module 'backend.main': No module named 'pydantic_core._pydantic_core'
error message.
This was incredibly frustrating — so much so that I was strongly considering opting for either EC2 or Fargate instead, though I ultimately decided to see it through as serverless compute was identified as a key requirement during discovery.
The issue stemmed from a mismatch between Lambda’s Python 3.12 runtime, which runs on Amazon Linux (x86_64), and my local macOS development environment (ARM64). Core Python packages such as NumPy, Pandas, and Pydantic contain compiled binaries, and therefore must be built on a compatible architecture to run successfully on Lambda.
Thankfully, the solution was relatively straightforward. I spun up a temporary Linux-based EC2 instance specifically to recompile Pydantic and the other impacted libraries. This appears to be a well-known workaround when working with compiled dependencies on Lambda, though it is not always clearly documented. Aside from a few inevitable hiccups assigning the correct IAM role and policies, I was able to repackage the libraries and upload them to Lambda without further issues.
For any Mac-based developer working with compiled Python libraries, this architecture mismatch will require a Linux build environment — whether via EC2, Docker, or another compatible approach.
Attaching WAFs to CloudFront: The us-east-1 Rule and Its Side Effects
The setup of the Web Application Firewall (WAF) presented the next major implementation hurdle.
The first issue arose when I mistakenly created a regional WAF in eu-west-2
(London). However, CloudFront only supports global WAFs created in
us-east-1 (N. Virginia). As a result, any attempt to attach the WAF triggered
InvalidParameterException errors. Matters were made worse by the AWS Console showing the
WAF as successfully attached, while the CLI reported it as unattached — causing confusion and delaying
debugging efforts.
The solution was to recreate the Web ACL in us-east-1 with Scope=CLOUDFRONT,
and attach it via the CloudFront Console rather than the CLI, which helped avoid
further validation issues. The core CloudFront learning here is that
all WAFs must be created and managed in us-east-1 to apply globally;
regional WAFs will consistently fail to attach.
Unfortunately, the complications did not end there. Because my rate-limiting rule (100 requests per 5 minutes per IP) lived inside the same WAF, it was also unable to take effect when the WAF failed to attach. This went unnoticed for a considerable period, as unrelated 403 errors created the illusion that the rule was functioning when, in reality, it was not active at all.
Ultimately, the rate-limit rule began functioning automatically once the WAF was properly attached in the correct region.
When Authentication Isn't the Problem: Debugging a CloudFront Red Herring
Authentication proved to be by far the most difficult aspect of the entire implementation, as it contained a myriad of issues which, on multiple occasions, felt insurmountable.
-
Hosted UI: Missing ‘Sign-in’ Behaviour
The first major blocker came from AWS Cognito’s Hosted UI being completely unresponsive when clicking on the “Sign in” button. This was due to importing the browser build ofoidc-client-tsinstead of the correct ESM module. The issue was resolved by switching to the proper ESM import:import { UserManager } from "https://cdn.jsdelivr.net/npm/oidc-client-ts@2.0.4/dist/esm/oidc-client-ts.min.js"; -
Callback Page Not Working / Login Loop
After redirecting from Cognito’s hosted authentication journey, the callback page either did nothing or displayedError: no authorization code returned. The root causes were incomplete handling of the OAuthcodeparameter and a slightly incorrect callback path. Switching from a raw token exchange script to the manageduserManager.signinCallback()function resolved the issue. -
Invalid Scope Error
A recurring error occurred where sign-ins redirected back to the callback page with:
This was caused by the Cognito App Client lacking theerror=invalid_request&error_description=invalid_scopeprofilescope — onlyemailandphonehad been selected. OIDC requiresopenidplus at least one ofemail,profile, orphone. Adding theprofilescope resolved the issue fully. -
Incorrect Front-End Behaviour Misdiagnosed as Auth Failure
At this point, it seemed like the entire authentication flow was cursed: the sign-in button didn’t work, the UI didn’t update, redirects failed, and Cognito occasionally displayed error messages. The behaviour was inconsistent and unpredictable, giving the impression of a fundamentally broken authentication system.
In reality, the authentication pipeline was implemented correctly. The real issue was that the front end was serving a stale JavaScript file. S3 object overwrites were silently failing, causing CloudFront to cache outdated assets. Once the correct JS bundle — with the properredirectUri, metadata, and module imports — was deployed, the entire flow snapped into place.
Ultimately, the outdated JS prevented event listeners from attaching, blocked UI updates, and stopped the PKCE flow from triggering. Cognito was throwing errors only because the old bundle was passing malformed redirect URIs. What looked like OAuth failures were, in reality, front-end deployment issues in disguise.
This experience was a powerful reminder that in distributed systems, what appears to be an authentication failure may actually be a front-end deployment issue.
Testing & Results
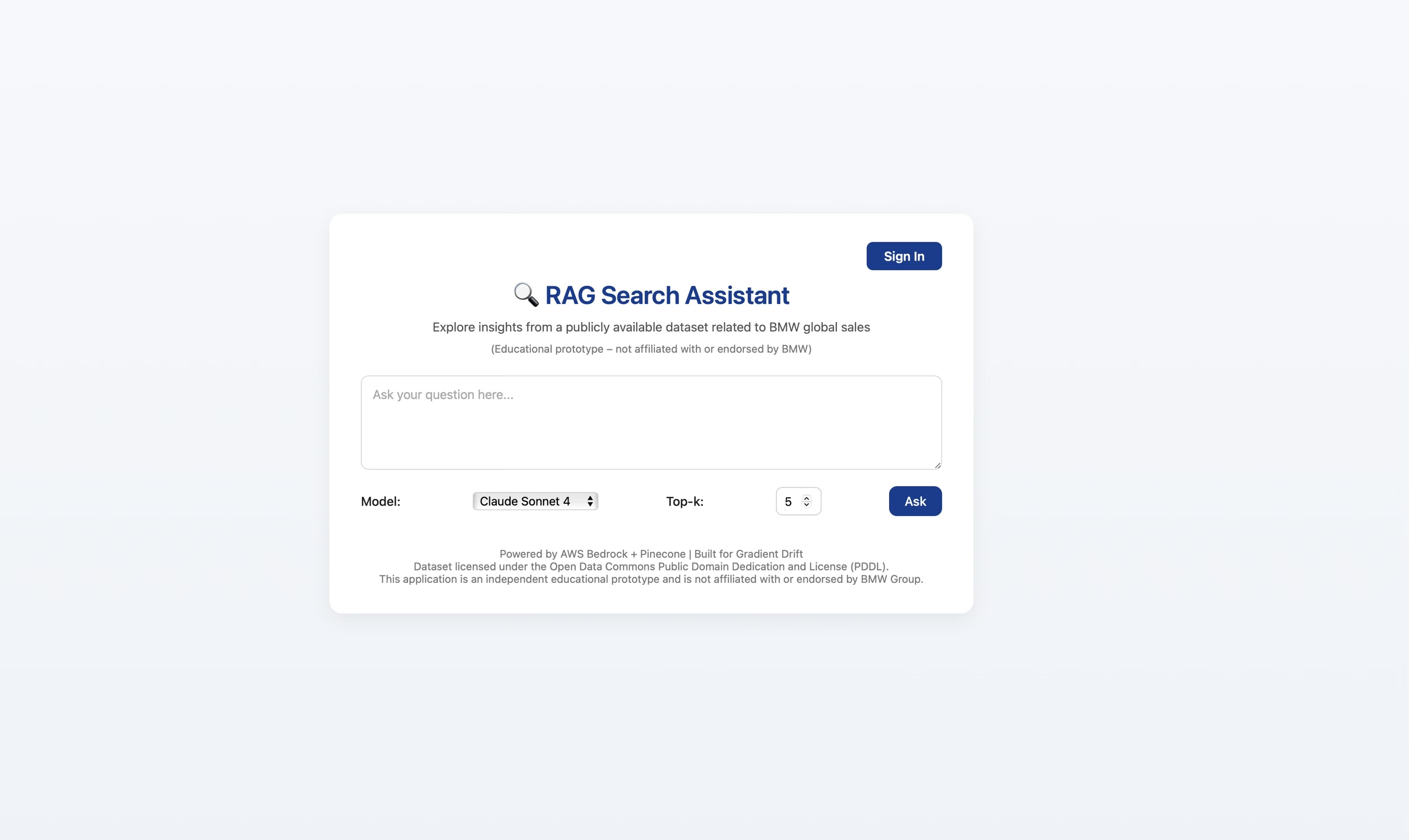
RAG Search Assistant — UI Snapshot
The screenshot below shows the final user interface for the RAG Search Assistant as deployed during testing. This capture reflects the production-ready layout, authentication controls, model selector, Top-k parameter, and query input surface used to perform evaluation.
Reflections & Lessons Learned
Security as a First Class Concern
Having previously walked away from many projects due to technical stalemates or shifting scope, it was deeply satisfying to see this project through and deliver a tangible product that met the majority of its goals. Fortunately, I was guided by a well-defined process that I have iterated and improved over time, which helped me anticipate critical issues and mitigate them early on.
That said, there were clear opportunities to improve how security was handled. While it was a key consideration at the start of the project, in hindsight it should have been baked into every feature rather than treated as a parallel stream. Many of the implementation challenges ultimately touched on security in one form or another.
Going forward, I’ll take greater care to analyse every component through the lens of its attack surface and potential threat vectors. I also intend to incorporate more rigorous testing and security hardening during design and delivery, in order to avoid the unacceptable outcome of a vulnerability slipping into production.
RAG and the Future of AI at Work
The RAG Search project provided an excellent opportunity to explore some of the core principles businesses grapple with when adopting AI into their organisations. Retrieval-Augmented Generation is clearly a critical enabler for businesses looking to leverage LLMs in ways that reflect internal context and data, while also reducing many of the reliability concerns that typically accompany this technology.
Natural language interfaces are emerging as a central pillar of the AI-native workplace. They offer a powerful, intuitive entry point for employees to perform higher-quality work at speed. In today’s climate, it’s difficult not to capture the interest of business leaders when articulating the concrete, near-term benefits of these tools.
One development I anticipate is the arrival of AI Enablement Officers — a new kind of internal role responsible for helping workforces adopt AI tools effectively. While these technologies are incredibly powerful, they are not self-explanatory. Great care must be taken not only to train users, but to foster a culture of responsible AI usage that acknowledges the risks of over-reliance and the potential loss of personal agency it can bring.
What’s Next
For my next project, I intend to explore many of the themes raised by the RAG Search Assistant in greater depth. I am especially keen to take any available opportunity to better understand how business leaders view LLM adoption, and to identify the practical solutions that enable responsible implementation at scale.
While RAG features heavily in today’s AI zeitgeist, Agentic Orchestration represents the other half of the enterprise AI equation. Where RAG Search helped clarify how businesses can understand what is happening inside their organisations, my next project will focus on Enterprise Execution — specifically, how AI can help organisations act intelligently across systems. This is where agentic systems come into play.
In addition, I am interested in exploring open-source solutions such as LLaMA, DeepSeek, Mistral, and Falcon. I also intend to explore Azure OpenAI, with a view to creating a multi-cloud solution spanning both AWS and Azure. This will provide an excellent opportunity to demonstrate how businesses can safely interact with AI systems in a way that addresses organisational concerns around security, data sovereignty, and compliance.